

Unlocking the Benefits of a Data Perimeter in AWS
When initially establishing a footprint in AWS, managing the security of workloads may seem easy. There are few users that need access, and the amount of data in AWS may seem manageable. However, the complexity of managing security at scale in AWS can settle in very quickly. Workloads are added, more users need access, and suddenly the prospect of securing your environment is daunting. By planning for this growth and designing security controls accordingly, we can prevent a lot of trouble down the road.
This is where establishing a data perimeter can help. AWS defines a data perimeter as
a set of preventive guardrails in your AWS environment you use to help ensure that only your trusted identities are accessing trusted resources from expected networks.
We implement this at three separate levels: resource, network, and identity.
The process of establishing a data perimeter in AWS can vary in length and cost depending on organization size, resources in AWS, complexity of the current setup, and more. However, at its core, a Data Perimeter is strategic rather than technical. While AWS provides dozens of tools to implement Data Perimeter concepts, the value of these tools can truly be unlocked only when a strategic plan is established. For guidance on the technical details of establishing a data perimeter on AWS, see the official AWS blog post. This blog aims to enumerate further the benefits of establishing a Data Perimeter.
Benefits
Following the Principle of Least Privilege
One of the key benefits of establishing a Data Perimeter is that you can granularly set permissions and follow the principle of least privilege to a great degree. This both limits the blast radius for your environment and gives you greater peace of mind that excess permissions weren’t granted due to a misconfiguration. Additionally, developer productivity can be accelerated since broader IAM permissions can be granted since there are resource-specific protections in place.
Consider the following example. An AWS environment has sensitive data stored in an S3 bucket that needs to be accessed by a trusted third party. To prevent accidentally oversharing external access, we can limit external access only from the third-party’s AWS account. Then, if we accidentally grant access to any other external AWS principals, this explicit deny statement will override it. An S3 Bucket Policy like the one below can be used to limit access at a resource-level to only trusted accounts:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "RequireAccessFromTrustedAccounts",
"Effect": "Deny",
"Principal": "*",
"Action": "s3:*",
"Resource": [
"arn:aws:s3:::<EXAMPLE-BUCKET>",
"arn:aws:s3:::<EXAMPLE-BUCKET>/*"
],
"Condition": {
"StringNotEqualsIfExists": {
"aws:PrincipalOrgID": "<MY-ORG-ID>",
"aws:PrincipalAccount": ["<THIRD-PARTY-ACCOUNT-A>"]
},
"BoolIfExists": {
"aws:PrincipalIsAWSService": "false"
}
}
}
]
}
Resource-level policies like the above S3 Bucket Policy are a key Data Perimeter technology. With this arrangement, the third-party business partner only has access to the S3 bucket and there is no concern of over-provisioning access. This is a simple example of how the principles of a Data Perimeter allow for fine-tuning and providing access at the resource-level without any additional identity-management overhead.
Avoid Network Exposure to the Internet
One major concern in the cloud is exposing resources with sensitive data to the internet. Establishing a Data Perimeter can help with this situation. Guardrails can enable necessary functionality and keep resources within private networks. Using tools like VPC endpoints to limit the amount of traffic traversing the public internet can greatly limit risk and give greater peace of mind to security teams still adapting to a cloud-first world.
For example, a data team is using Redshift to store PII and has a need to process this data on an EC2 instance in a private subnet within your trusted VPC. Due to the sensitive nature of the data, your security team is concerned about the data traversing the internet. VPC endpoints, a core technology of a Data Perimeter setup, allow a private connection between your VPC and an AWS product, in this case, Redshift. The traffic is configured to run through the VPC endpoint back into your private subnet using the AWS backbone, avoiding the public internet. Thus, your security team can be assured that the traffic is secured in transit.
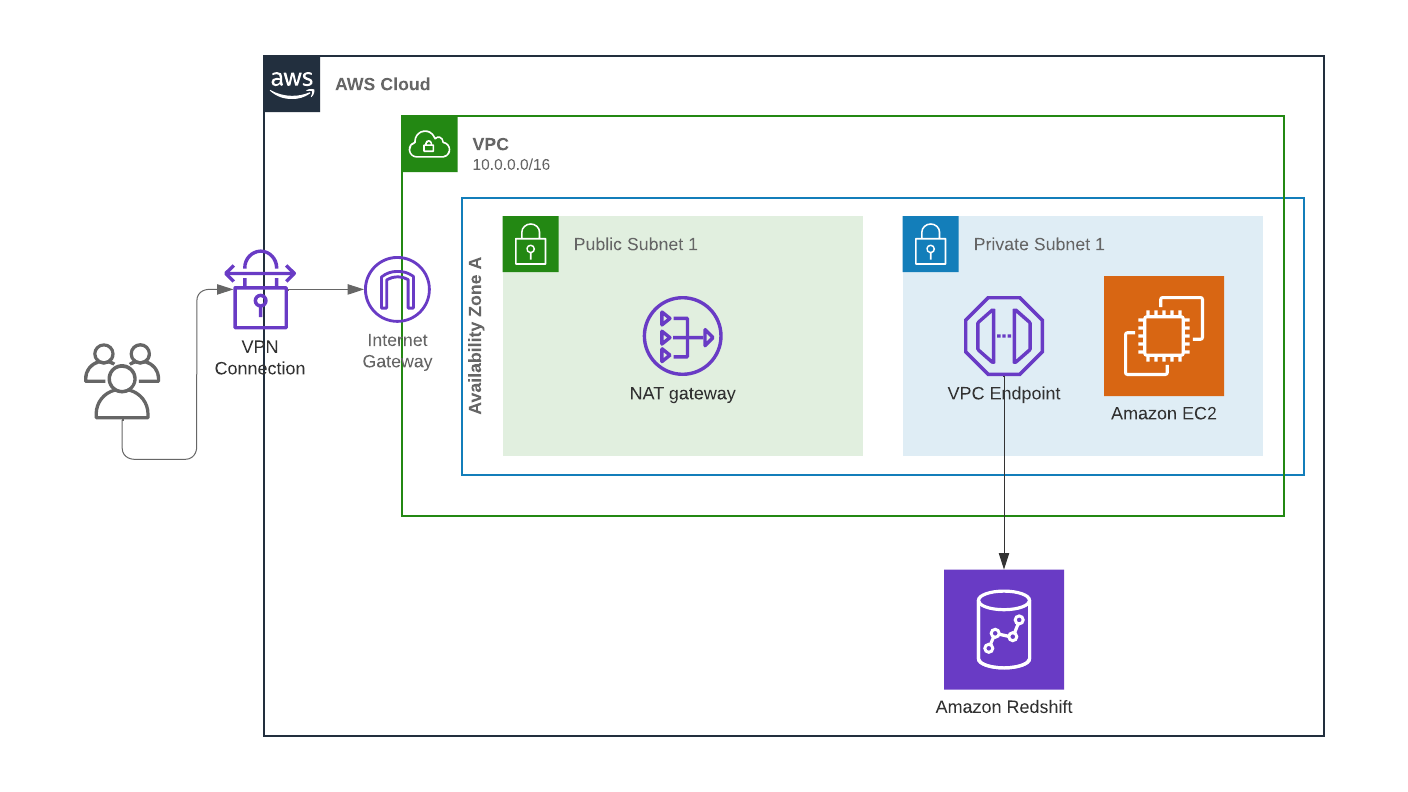
Avoid Network Exposure to the Internet
Simplify Meeting Compliance Requirements
Many organizations are still adjusting to compliance in the cloud. The technologies and processes that they worked with 10 years ago may or may not be applicable in the cloud world, and having sensitive data or workloads in AWS may make them uncomfortable. Further, if the data includes PHI, credit card data, or other specific data types, strict compliance requirements may apply. With these compliance requirements in mind, security teams’ instinct may be to limit the amount of use in AWS, reducing the value gained from being in the cloud and slowing organizational cloud adoption.
With a Data Perimeter implemented, compliance can be built into the guardrails of the AWS infrastructure. During the planning phase of the Data Perimeter effort, an organization can explicitly call out which compliance frameworks they are subject to and which controls apply to their AWS environment. A mapping exercise can then be undertaken to map these necessary controls to specific AWS technologies, which can then be implemented as a part of that effort. While this may involve a significant amount of work upfront, it will greatly reduce the effort as the environment scales since compliance controls are now at the root of the environment.
For example, say that a health analytics startup wants to store PHI data on AWS in a DynamoDB database. Due to aspects of the HIPAA Security Rule, your security team needs to employ strict access controls in the environment. By using Service Control Policies (SCPs), actions taken on resources such as S3 buckets can be restricted at the principal level. For example, the following SCP restricts S3 actions on a given bucket to a principal within your organization:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Deny",
"Action": "dynamodb:*",
"Resource": "[ "arn:aws:dynamodb:::<EXAMPLE-TABLE>", "arn:aws:dynamodb:::<EXAMPLE-TABLE>/*" ]",
"Condition": {
"StringNotEquals": {
"aws:ResourceOrgId": "${aws:PrincipalOrgId}"
}
}
}
]
}
Conclusion
Establishing a Data Perimeter is no small exercise, especially if your organization’s footprint in AWS is already significant. However, the benefits of establishing a Data Perimeter in AWS can greatly outweigh the financial and time-related costs of this effort. Between the greater level of defense in depth and greater peace of mind, the benefits of a Data Perimeter are worth the upfront time and financial investment, especially as your AWS footprint scales.