
Improving CIS Benchmark Alerting and Remediation in AWS

SecOps Automation
Why Automate Security Operations?
By now, many organizations have realized that there are significant benefits to moving to the cloud and have moved past their initial fears. However, oftentimes teams are still not taking full advantage of the new capabilities available to them, specifically in the area of Security Operations and automation. Many organizations have carried over manual processes from on-premise environments, which are typically filled with red tape. Now teams are even more strained because they may have to manage on-premise and/or multiple cloud environments with the same sized staff. One way to move past this hurdle and optimize a security program in the cloud is to take those old manual processes and modernize them. In the cloud, this typically means automating as much of these processes as reasonably possible.
There are major benefits to teams that can incorporate automation into their daily security processes. Just a few include:
- Filtering out noise at scale - Most organizations collect large amounts of data and logs from many different sources. Mature organizations may have Security Information and Event Management (SIEM) systems in place to attempt to sift through and analyze this data. But are these systems designed to operate rapidly at cloud scale? How quickly can they identify an issue, and can they initiate an automated response? Moving filtering, categorization, analysis, and even remediation from a SIEM to a service closer to the data collection point can significantly reduce the noise by only sending relevant data to a SIEM or directly to analysts. It also allows for quicker identification of potential issues and remediation.
- Near-real time rapid response - Any time human or manual steps, such as investigations or approvals, are involved in a process there is inevitably delay and a higher chance of mistakes appearing. This provides attackers with more time and opportunity to damage or compromise your system and data.
- Reduction of toil - Repetitive tasks can be automated away from Security Operations staff. This reduces potential human errors of doing routine activities and usually increases your team members job satisfaction as they can reallocate their time to more interesting and critical work.
Are you looking to continually increase the system capacity for your SIEM, and in turn increase costs? Do you want your team members to spend significant amounts of time monitoring investigating CloudTrail events, VPC flow logs, or low priority finding that appears in SecurityHub? Should they spend time manually remediating by reverting changes to security groups or NACLs that developers accidentally made? Probably not. Typically security teams are understaffed, so anything that can be done to reduce their workload and remove repetitive tasks is welcomed. This is where process automation will drastically improve your response time and allow your smaller team to scale their workload exponentially. For the remainder of this article we are going to walk through a specific example of automation that can be used as a starting point to implementing more advanced automation workflows.
Improving CIS Automated Alerting
A first step many organizations perform when configuring a security baseline in AWS is to implement the Center for Internet Security (CIS) AWS Foundations Benchmark Standards. The benchmark provides guidelines for a secure infrastructure and application architecture. In addition, it includes some basic automation recommendations, specifically around automated alerting. Standards 4.1 through 4.15 in the Foundations Benchmark v1.3.0 dictate how to implement automated alerting when specific AWS API actions, possibly representing malicious activity, occur. This is a great first step when wading into automation, but there are some limitations with CIS’s implementation guidance as you try and mature your automation suite.
CIS’s recommended approach for automating alerts on potentially malicious API calls is to use CloudWatch Logs and metric filters. This implementation requires CloudTrail events to be forwarded to a CloudWatch Logs group. A metric filter per alert is then applied to that log group. The filters monitor the incoming CloudTrail events and maintain a count of when defined matching patterns are found that may signal incidents or policy violations. When a specific number of these patterns are detected in a predefined time period, the metric filters trigger an alarm that then publishes a message to SNS stating the threshold has been reached. This approach works great for automating alerts, but it does not lend itself well to advanced workflows, like automated remediation. Specifically:
- Lack of contextual data - When using metric filters, you lose most of the data around the event. A metric only provides a count on how many times a pattern was matched. It does not contain details on the specific events that matched the pattern. So when an alert triggers, it can tell you that some NACL was modified, but it cannot tell you which NACL, who made the change, or what was changed in the NACL. Without this information, a security analyst needs to now sift through CloudTrail logs to identify the actual violation that triggered the alert or create additional tooling to collect the necessary information. This also makes automated remediation difficult because the data required to perform the remediation action is not readily available.
- Limited alert targets - CloudWatch alerts allow for delivery of messages to targets. A target is ultimately just an endpoint that can receive messages or initiate actions. CloudWatch alerts allow for targets to be SNS topics or execution of a few EC2 related actions. The alerts cannot initiate more advanced target actions like executing Lambda’s, executing SSM commands, or calling third party APIs. This means any automation coming from CloudWatch alerts typically needs to begin with SNS message delivery. And while it is possible to subscribe services like Lambda to the SNS topic, the lack of contextual data delivered to the SNS topic limits what services like Lambda can act upon.
- Delayed response - As mentioned earlier, time is of the essence when it comes to alerts and automated responses. Unfortunately CloudTrail can take up to 15 minutes to deliver event records to CloudWatch. Once the event is in CloudWatch and the metric filter triggers, there are still evaluation periods and thresholds that must typically be met before an alert is actually published to SNS. This delay can be costly if the alert was triggered by an attacker gaining entry to your system.
How can we address the limitations in the CIS recommended implementation? The key is taking advantage of AWS’s EventBridge service to create a fully event driven SecOps architecture instead of relying on CloudWatch Logs. EventBridge is a serverless event bus, and the successor to CloudWatch Events. It provides a default event bus that many AWS services, over 90 at this time, automatically emit a variety of events to. This includes CloudTrail, which streams every event it logs to the bus in near real time. Every event that is delivered to the bus can be filtered on via rules, and then acted upon. When an event matches a pattern defined in a rule, the rule will then initiate an action against a target such as sending a notification to an SNS topic, executing a lambda or ECS task execution, posting to a custom API, or about 20 other available targets. We can take advantage of EventBridge rules to monitor CloudTrail events as opposed to CloudWatch metric filters. The benefits realized by this approach include:
- Full event context - The entire CloudTrail event record that the rule matched is delivered to targets. This means all the data around the event is readily available to act upon.
- More target options - There are over 20 different targets supported by EventBridge rules, including SNS, Lambda, 3rd party APIs, and even other event buses. Each rule can also have up to 5 targets. This allows you to create automation targeting multiple systems, or services, without the additional complexity of chaining services (though that is still an option if desired). The number of possible targets, combined with the full event data provided, makes it much simpler to implement automated remediation actions.
- Near-real time response - While CloudWatch logs can have up to a 15 minute delay, events are typically written to the EventBridge bus in near real time. For services like CloudTrail, it is rare that an event and pattern match takes over a minute.
Implementing CIS Alerts and Automated Remediation with EventBridge
Knowing the benefits that EventBridge can provide, let’s walk through how using EventBridge for CIS alerting works.
CloudTrail events are automatically written to the default EventBridge bus. This means there is no need to set up CloudTrail forwarding to CloudWatch logs for this solution. Instead, we will create EventBridge rules that monitor the default bus and trigger when a pattern match occurs. When the rules trigger they will send a copy of the entire CloudTrail event record to an SNS topic. This SNS topic can then be subscribed to and receive alerts. In addition to SNS, the rules will also forward the CloudTrail event record to an auto-remediation Lambda function. In our example, this Lambda will only remediate a single type of event (such as the stopping of CloudTrail logging) but it can be easily modified to address the other findings you may want to auto-remediate. The high level architecture deployed is shown below.

Implementing CIS Alerts and Automated Remediation with EventBridge
We have created a Github repository that contains all the code necessary to deploy all 15 of the CIS alerting rules and supporting resources using either CloudFormation or Terraform. It implements the architecture shown above. See the README files in the repository for specific steps to use the templates.
Manual Deployment Walkthrough
For demonstration purposes let’s walk through the creation of one EventBridge rule via the console instead of using the IaC options available in our Github repository. Specifically we will create a rule to alert on changes to CloudTrail trails and implement a remediation rule that will automatically restart logging on a trail if it is stopped (CIS Benchmark control 4.5 in v1.3.0). These steps will assume that you have an SNS topic and Lambda already in place. The IaC templates we provide will create these automatically for you. Also, when deploying anything, keep in mind that EventBridge is a region specific service.
- We first open the Amazon EventBridge console and create a rule.

Open the Amazon EventBridge console and create a rule
- We then name our rule and provide a description. We will be alerting on CloudTrail changes, so name it accordingly.
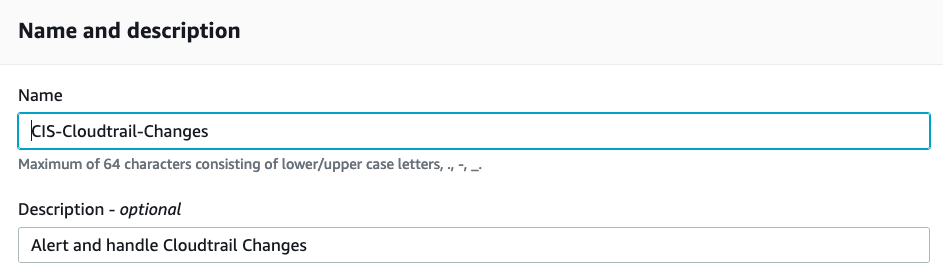
Name our rule and provide a description
- Next we define the pattern the rule will look for within the CloudTrail events. We are going to monitor all events from
aws.cloudtrailthat appear on the default EventBridge bus. When those events appear, our rule will run a pattern match against the event looking for API calls that includeStopLoggingand others. You can see a screenshot of the example CloudTrail pattern we want to match against below. There are many other predefined patterns available for other use cases, including many other services besides CloudTrail. We strongly recommend taking a look at the predefined patterns to get an idea for what else is possible with EventBridge.
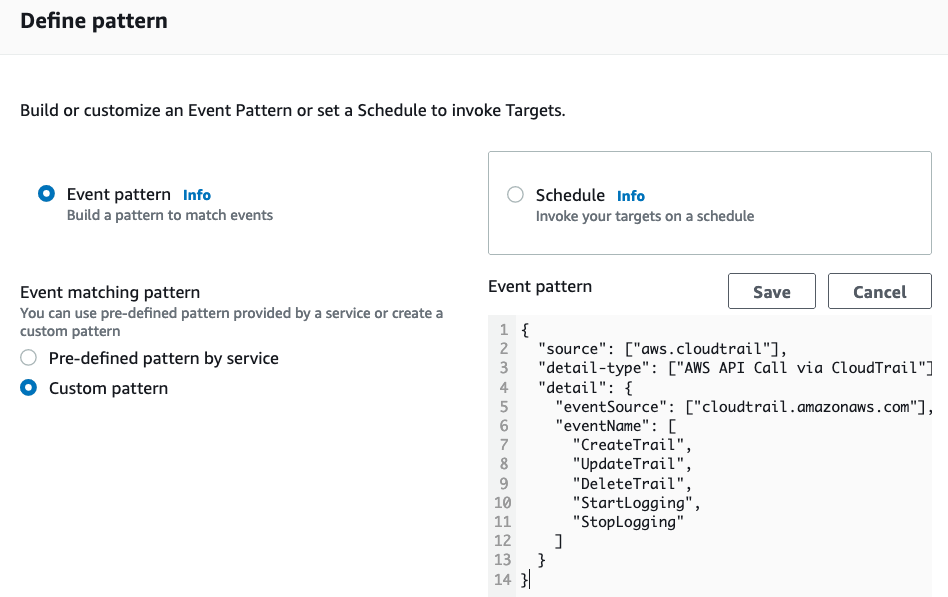
Define the pattern
- Next we have the option of using the default AWS event bus, creating a new event bus, or choosing an existing custom one. Since we need to monitor CloudTrail events we must choose the AWS default bus. This bus is where AWS services natively emit events. We would use custom buses if we wanted to consolidate events from multiple buses or if we had custom applications that could write to their own bus.

Select event bus
- Lastly, we define our targets and the actions to take when a pattern match occurs. We have the option to add up to five targets to which the rule can send the event. For our use case we are going to create one target for an SNS Topic we created called CIS-Alerts and a second target to a Lambda we created called EventBridge-CIS-Remediation. Both are automatically created if you use the IaC templates in our Github repo. For this demo we’ll leave everything else default and create the rule.
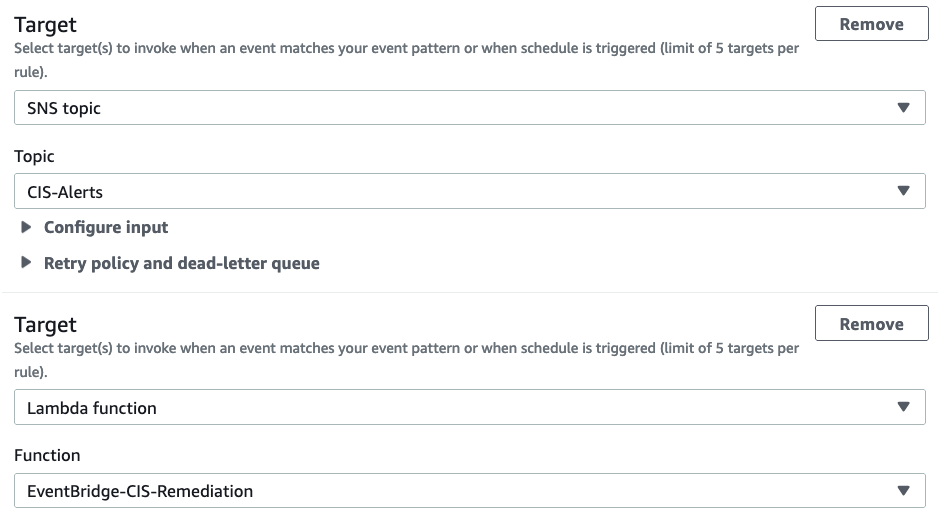
Define targets and actions
- At this point the rule is active. If any of the CloudTrail API events match the pattern we defined, the rule will send the full event record to the SNS topic and the Lambda. We can confirm it is working by subscribing our email address to the SNS topic. This will then deliver the full event to our email. With this basic implementation, the event delivered to SNS and our email is unprocessed. The triggering issue won’t be easily readable or identifiable unless you understand how to read the JSON based CloudTrail event records. To receive clean and human-readable email notifications we can have our Lambda process the event and create an appropriate message. Besides the SNS message, we can also confirm our current Lambda function processes the event when invoked and performs the desired remediation action. Our simple Lambda automatically restarts a CloudTrail trail if logging is stopped. So to confirm functionality we just stop any trail in the same region and it should be automatically restarted. This Lambda can be easily expanded to handle other remediation use cases in the pattern as well or to create more user friendly messages to post to SNS.
With this setup we have improved on the CIS CloudWatch Metrics / Alerts remediation approach by sending enriched data to SNS and Lambdas that includes all the data necessary to perform remediation actions. We are also able to send out SNS notifications and execute a Lambda with a single rule eliminating the need for complex chaining. To really productionize this you will want to further develop the Lambda to handle other event types and integrate the SNS notifications with any desired communication channels (Email, Slack, SIEMs, PagerDuty, etc. You could also create another Lambda that creates a formatted notification message with only the required data and then delivers it to some communication channel, instead of posting the raw message to SNS.
Next Steps
This was just a basic example of how EventBridge can be used to improve compliance with CIS monitoring and alerting standards. But EventBridge can be used to automate a multitude of event-driven security processes and use cases. You can use it to do things such as:
- Develop tiered notification processes based on severity level.
- Implement advanced multi-step auto-remediation and incident response.
- Integrate targets with external system calls to endpoints like ticketing systems.
- Consolidate event buses from multiple accounts for a single monitoring location.
- Alert or respond to organization wide SecurityHub findings from a single delegated administrator account.
- Kick off automatic vulnerability scans with AWS Inspector when GuardDuty identifies potential issues.
- Automate disabling of access keys or IAM principals that may have been compromised or violate policy.
- Revert a Security Group rule change that violates policy.
- Revert public S3 access if a bucket policy is modified to grant public access.
If you are interested in learning more about building out security automation with EventBridge, or implementing general best-practice SecOps capabilities in AWS, reach out and we can discuss how we can help. ScaleSec is an AWS Advanced Partner with Security Competency in Governance, Risk, and Compliance. We can help accelerate your SecOps maturity with our training, analysis, architecture, and engineering capabilities.