GKE Workload Identity
Traditionally, there have been security challenges with the methods used for Kubernetes workloads running on GKE authenticating to Google Cloud services. This article will cover how GKE Workload Identity addresses the security issues with the previous methods, give an overview of how GKE Workload Identity works, and provide some security considerations when implementing GKE Workload Identity.
Background Information
It’s helpful to cover some terminology and background information to better understand GKE Workload Identity.
There are two levels of access in GKE. There is GCP Identity and Access Management (IAM), which operates at the GCP Resource level, such as GCP projects and the GCE compute nodes that make up the GKE cluster. Then, there is Kubernetes Role-based Access Control (RBAC) which operates within the GKE cluster and namespace level and is used to manage objects within the Kubernetes cluster, such as deployments, namespaces, etc. There are also service accounts at both the GCP IAM and Kubernetes levels.

GCP IAM
A GCP service account is an identity that an application can use to make requests to GCP resources and APIs. The permissions assigned to GCP service accounts are managed by Cloud IAM. Kubernetes service accounts are part of the Kubernetes cluster, and provide an identity for processes running in your GKE pods.
What if a workload running within GKE needs to access a Google Cloud resource, such as a BigQuery database or Cloud Storage bucket? GKE Workload Identity helps solve that problem. In order to appreciate the security advantages of GKE Workload Identity, we can first look at the methods that were traditionally used to allow Kubernetes workloads to authenticate to GCP APIs.
The Old Ways to authenticate GKE Workloads to GCP
Prior to Workload Identity for GKE, there were two primary methods for authenticating GKE workloads to Google Cloud APIs: using GCP service account keys as Kubernetes secrets, and using the GKE node’s service account. The following is an overview of each method, as well as a brief discussion of their security pitfalls.
Service Account Keys as Kubernetes Secrets
This was one of the most common ways for GKE workloads to authenticate to Google Cloud services. GCP security accounts can have user-managed keys associated with them. In this method, GCP service account keys were generated and downloaded, and stored as Kubernetes secrets. Service account keys are long-lived credentials akin to a password, and Google recommends against using them unless there is no alternative.

CIS Benchmarks - IAM Findings
There are several security issues with this approach. There is a tremendous management overhead associated with service accounts, especially if the required management processes are not automated. Service account keys need to be properly managed, stored in a credential management system, and rotated every 90 days, according to CIS GCP Foundation Benchmark.
Proper credential management comes with many challenges, and can involve a lot of engineering toil and undifferentiated heavy lifting, especially as the number of GKE clusters in an organization increases. Guardrails around service-account keys are important, but they do not guarantee that a service account key cannot be accidentally or maliciously exposed.

Kubernetes Secret
Given that service-account keys are long-lived credentials that do not expire for ten years, this provides plenty of opportunity for a malicious actor to discover them. Additionally, Kubernetes secrets are base64 encoded, and anyone who is granted access to Kubernetes secrets can trivially convert the secret contents to cleartext.
As there are more secure alternatives to service account keys (and not just in the case of Kubernetes), service account key usage in general should be minimized.
Using the GKE Node’s Service Account
Another way for GKE workloads to authenticate to GCP is by using the GKE node’s service account. GKE nodes are an underlying compute instance, and it is possible to run your node as any GCP service account in your project. If you do not specify a service account during node pool creation, the node is assigned the Compute Engine default service account.
The main security concern with this approach is that it violates least-privilege. By default, the Compute Engine default account has the Editor role, which is overly permissive. If this account was compromised it could potentially have a huge blast radius. Even if a properly-scoped service account is created, the Compute Engine service account is shared by all workloads deployed on that node. This also goes against the principle of least privilege on GKE, since you might only have one pod in the node that needs to be able to access a GCP service, but every other pod on the node should not.
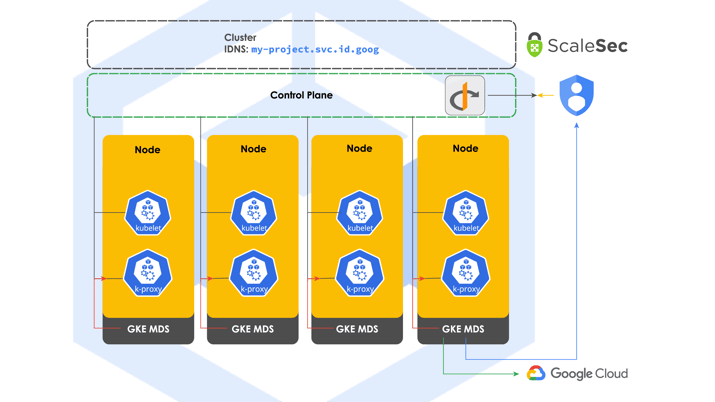
GKE Workload Identity
GKE Workload Identity addresses the security shortcomings presented by the two traditional methods of authenticating GKE workloads to GCP services. GKE Workload Identity works by binding a GCP service account to a Kubernetes service account. The workload running under the Kubernetes service account will then be able to impersonate the GCP service account to access GCP resources and APIs. Here is the token exchange flow taken from this Cloud Next ’19 video introducing GKE Workload Identity:
GKE Workload Identity
- The GKE Metadata Server requests an OpenID Connect (OIDC) signed JSON Web Tokens (JWT) from the Kubernetes API server.
- The GKE Metadata Server then uses the OIDC signed JWT to request an access token for the Kubernetes service account from GCP IAM.
- GCP IAM validates the bindings and OIDC signed JWT against the cluster’s OIDC provider and returns an access token to the GKE Metadata Server.
- That access token (for K8s service account) is sent back to IAM, and a short-lived GCP service account token is issued to the GKE Metadata Server.
- The GKE Metadata Server passes the GCP service account token on to the workload.
- The Kubernetes workload uses the GCP service account token to access GCP services.
One of the biggest advantages of GKE workload identity is that it eliminates the overhead and security risks involved with managing service account keys. Workload Identity issued credentials are short-lived tokens that expire within hours, which greatly reduces the opportunity for compromising a credential. Furthermore, the credentials are managed by Google, which removes the burden of managing service account keys, and reduces the risks of improperly managed service account keys. Enabling GKE Workload Identity and running the command to bind a Kubernetes service account to a GCP service account is a relatively straightforward process, and GCP offers detailed instructions on using Workload Identity here.
Another advantage of GKE Workload Identity is that it aligns better with granting least-privileged access. GKE Workload identity works by connecting a Google Service account to a Kubernetes Service Account. This gives the workloads running under the Kubernetes service account the access of the Google service account, allowing it to access GCP services. As long as both the Kubernetes service account and the Google service account have properly scoped permissions, using GKE Workload Identity follows least-privilege far better than using the GKE Node’s Service Account. That said, GKE Workload Identity uses the concept of an Identity Namespace, and the next section will explain how it is possible to give your Kubernetes service accounts unintended access.
Identity Sameness
GKE Workload Identity introduces the concepts of “Identity Sameness”. When Workload Identity is enabled on a cluster, the Google Cloud project gets a single identity namespace. An Identity namespace is an IAM construct that is currently unique to GKE.
IAM verifies or “names” a Kubernetes service account with the following information:
PROJECT_ID.svc.id.goog[KUBERNETES_NAMESPACE/KUBERNETES_SERVICE_ACCOUNT]
- PROJECT_ID.svc.id.goog is the identity namespace created by GKE.
- KUBERNETES_NAMESPACE/ is the namespace of the Kubernetes service account.
- KUBERNETES_SERVICE_ACCOUNT is the name of the Kubernetes service account making the request.
Essentially, it is possible to have two (or more) discrete GKE clusters, but if they have an identically named namespace AND these namespaces have identically named Kubernetes service accounts, then they will be treated the same by the GCP project’s identity namespace. Both Kubernetes service accounts would be able to impersonate the same GCP service account. In other words, it is possible to give the same access to a Kubernetes service account in a different cluster that you did not intend to.

Image adapted from: https://youtu.be/s4NYEJDFc0M
This could be used to an application’s advantage, a use case being if there is a namespace across multiple clusters that has the same function. As an example, if there is a “logging” namespace in every cluster, they could have an identically named Kubernetes service account that has the same permissions across clusters, and be able to impersonate the same GCP service account. However, some applications might want to avoid a pattern where multiple kubernetes service accounts can authenticate using the same GCP service account. In that scenario, the GCP documentation recommends either placing individual GKE clusters in separate projects, or having distinct namespace names across GKE clusters in a project.
Summary
GKE Workload Identity is the most secure and convenient way for GKE workloads to authenticate to GCP services. It removes the management burden and security risks involved with managing service account keys, and it makes it easier for workloads to follow least-privilege. More information can be found in the GCP documentation.
Want to ensure maximum security for your GKE Workloads? Contact us now for expert help with implementing GKE Workload Identity.