

Effective Documentation Using Data Modeling
In an earlier article, ScaleSec’s Michael Flanigan discussed documentation and why it matters.
In this article, we’re going to build on that foundation using Data Modeling as an effective way to organize a domain of knowledge and target an intended audience with the documentation.
Why Documentation Matters
Let’s Set the Stage
The use of effective documentation in this article is intended to mean:
- A reputable and authored source of truth that is trusted by an audience.
- Documentation that has contributions over its lifecycle from other colleagues or stakeholders within an organization.
- Documentation that can articulate its intent well (such as an Operations Guide that stays on theme from start to finish).
In software engineering, data modeling is the process of creating a data model for an information system. In repurposing for use with documentation, the “information system” can be an application stack, service, or some other defined system.
The data model is informed by different levels of technical and non-technical focus depending on the model context. We’ll define those model types in relation to documentation later in the article.
Data Modeling and Documentation
When authoring a document, you are usually biased towards writing in a voice that is familiar to you. This translates to you being able to write to an audience you empathize with naturally. Oftentimes, however, you’ll have to write to an audience that is different than your “natural voice.” It is crucial to take a step back from your point-of-view and consider a wider target audience in order to write more effective documentation. Data modeling provides some helpful guardrails for the author to corral a document’s focus to its target audience proactively.
There are three types of models:
Conceptual — Describes why the model is needed. This macro-level model is generally driven by non-technical requirements and created by leadership, project sponsors, and architects. This can be supported by a High-Level Design, or HLD.
Logical — Describes how the model is realized; Describes the Conceptual model in greater detail. This model type is the bridge between technical and non-technical teams. Architects, in an advisory capacity, and engineers are the intended audience with this model.
Physical — Describes what is used to deliver the Logical model. This micro-level model informs what the technical delivery and operations teams will use. Engineers, in a technical lead capacity, and operations teams are the intended audience at this tier. This can be supported by a Detailed-Level Design, or DLD.
Here’s a sample description demonstrating the interplay between models:
 |
 |
 |
Conceptual Model - WhyConceptual Technical and non-technical requirements for the business. |
Logical Model - HowLogicalTechnology selection to support technical and non-technical requirements. |
Physical Model - WhatPhysicalVendor and service selection details, IP addressing schemes, migration plans, as-built documentation. |
While the Physical model will support capturing the state of the environment at the end of a project, an alternative means of tracking environment changes during its lifecycle is recommended.
Data Reuse through Data Models
Data Reuse through Data Models
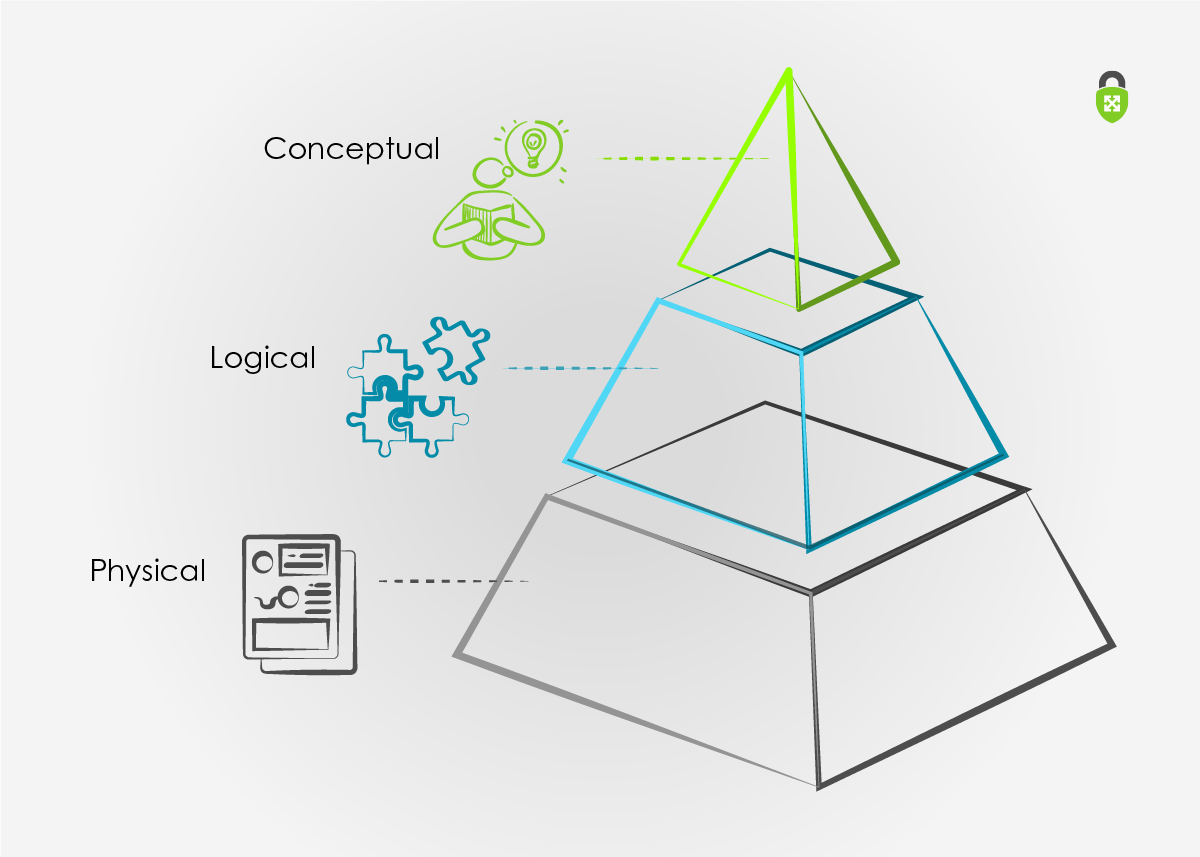
Describing the model as a pyramid with Conceptual on top, Logical in the middle, and Physical on the bottom will support describing data reuse as a top-down or bottom-up authoring exercise.
The pyramid illustration for data models infers that there’s a common theme among the three data models. This common theme supports getting meaningful data reuse to reduce the amount of repeated work necessary to deliver targeted documents that align with the audience’s motivations.
Top-down best aligns with new, or greenfield, environments. Armed with the conceptual model, you’re also able to infer how deep and broad the subsequent models need to be to align with the level of detail required to satisfy your audience.
Bottom-up supports documenting already existing, or brownfield, environments. Documenting the Physical model, since it already exists, is an exercise in how far/deep you should document the current environment before starting to work backward towards the Logical and Conceptual models.
A bottom-up approach can feel overwhelming, especially if the Logical and Physical layers are not present as a guiding light. Don’t let that overwhelming feeling stop you from getting started. Use this as an opportunity to true-up and re-familiarize yourself with the subject matter.
If you’re doing this proactively as a true-up exercise, take advantage of the reduced business pressure by metering out your investigation in a consistent fashion.
Translating your data models to your target audiences
Translating your data models to your target audiences
Armed with the data models used to inform your documentation and the interplay between models allowing for rich data reuse, you’re now enabled to deliver documentation catering to your target audiences.
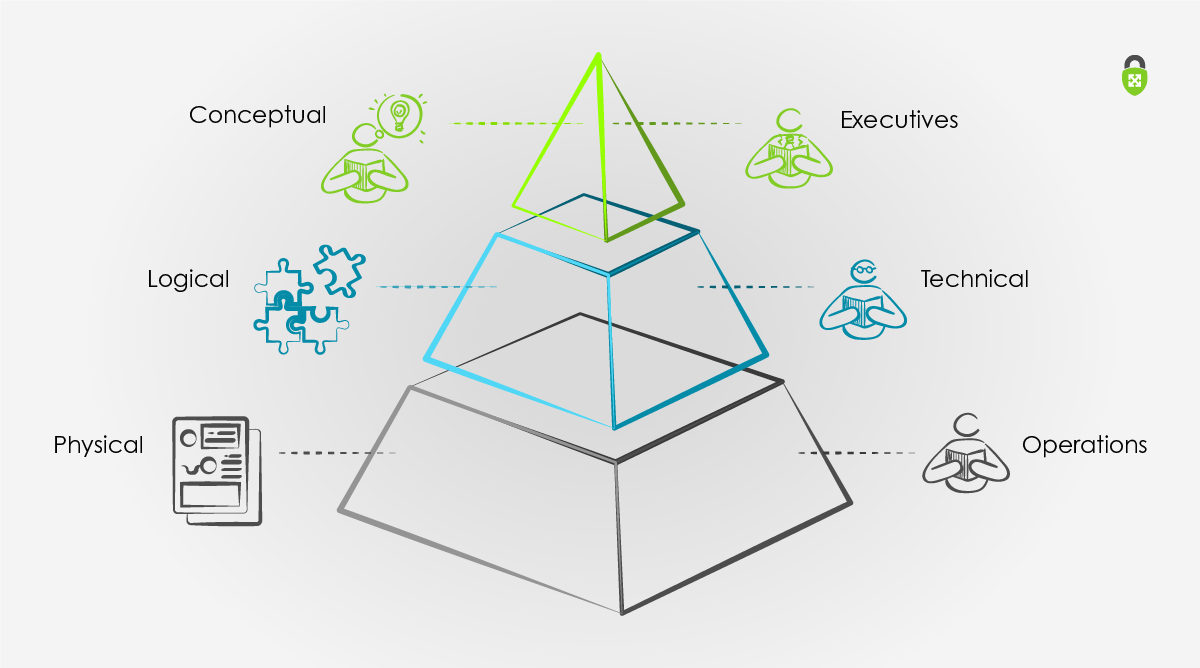
Conceptual model artifacts are recommended for an executive leadership audience. As such, it’s recommended that the primary focus be on how the “information system” delivered on their business success criteria.
Conceptual model artifacts: An Executive Summary, usually 1–2 pages, and an HLD.
Logical model artifacts are recommended for technical stakeholders and technical leadership and can enable education opportunities with their target audiences. Empathizing with technical and non-technical issues raised during the engagement, incorporating those contexts back into the documentation and using logical artifacts to answer those issues is a great way to become a trusted advisor.
Logical model artifacts: Detailed Discovery Artifacts, Deployment Plan, and multiple HLD’s that are a layer of detail deeper than the Conceptual model. HLD’s are derived by logical grouping appropriate for the engagement (i.e., app landscape, app stack, service stack, etc.)
Physical model artifacts are recommended for operations staff and other members responsible for service delivery within the organization.
Physical artifacts: IP Addressing and Resource allocation details, As-Built documentation, dependency mappings (inferred from Infrastructure as Code), DLD’s of the Logical HLD’s, documentation to contextualize
Getting Additional Value from Your Artifacts
Leveraging the diverse business perspectives that come from the data models, you can realize additional value in unplanned ways. For example, your organization has new compliance requirements that need to be met and you need to provide compliance documentation about your environment to auditors. Ideally, your artifacts may enable you to show your documentation as-is since it directly addresses an auditor’s ask. Or, you’ll be able to leverage your documentation sets by mixing and matching data across models to deliver a document in an unplanned context in a shorter period of time.
Benefits of Data Modeling for Documentation
In closing, using a data modeling strategy for documentation helps:
- Provide a comprehensive view of the model’s subject from a diverse blend of technical and non-technical perspectives.
- Accelerate creating your models via data reuse using a top-down or bottom-up modeling strategy.
- Authors target documents that better aligns with the audience’s needs using the developed data model or models as a springboard.
- Expedite new artifact creation through documentation reuse enabled by working through the data models.