

Data Loss Prevention on Google Cloud
Data protection is top of mind when it comes to securing workloads in the cloud. In a recent survey conducted by Gartner Research, 75% of technology leaders indicated that data protection and backup in the cloud was the most impactful project in their business. Enhancing visibility and engineering protective measures for data in the cloud is a priority for many businesses when it comes to managing data privacy and risk. One useful tool to gain insights into potentially sensitive data in Google Cloud Platform (GCP) is Cloud Data Loss Prevention (DLP). In this article, we will explore two common use cases for the Cloud DLP API: de-identifying data for batch and stream data.
Cloud DLP
Cloud DLP is a fully managed service offered by GCP that allows organizations and individuals to inspect, identify, and transform both structured and unstructured data. Using over 120 built-in infoTypes, Cloud DLP can classify many types of data such as phone numbers, credit card numbers, and email addresses. In addition to the built-ins, custom infoTypes can be created which are useful for scanning non-standard sensitive data such as account numbers and intellectual property that are stored in the cloud.
Cloud DLP can be used via the GCP Console or the Cloud DLP SDK. Each workload is called a Job and uses either Inspection Templates or De-Identification Templates to process data.
De-identifying Data
Cloud DLP can secure existing data at rest and protect the privacy of a dataset for useful analysis by transforming the data in a reversible or irreversible fashion. Tokenization (also known as masking or pseudonymization) uses a data encryption key (DEK) to de-identify data. This data can then be identified again using the DEK that was used to encrypt it. Because the encryption is deterministic and reversible, it is important to protect the DEK and only use it in trusted areas. Irreversible de-identification, akin to hashing, also uses the DLP API but instead uses an ephemeral key to transform data into an unreadable form. This unidirectional method of de-identifying data ensures that the key that was used to perform the transformation is immediately discarded after the call to DLP API has been done.
There are pros and cons to both approaches, however the general advice is to utilize tokenization if the data that you are working with may need to be re-identified at a later time (such as data analytics workloads, meeting compliance requirements, or for forensic purposes). If the goal is to simply identify sensitive data and then redact it, using the hashing method would be recommended to reduce the amount of controls that would have to be implemented to protect the DEK used for de-identification.
Data Loss Prevention for Batch Data Processing
Google Cloud provides many articles showing how to implement Cloud DLP to scan services such as Google Cloud Storage (GCS), BigQuery, and Datastore. For this collection of services, data is collected over time and then analyzed by the Cloud DLP API - this is known as batch processing. Batch processing for the Cloud DLP API typically requires setting up a cron job scheduler, configuring a scheduled inspection via the console UI, or setting up a service such as Dataflow or Dataproc to periodically process data through API calls to Cloud DLP. Cloud DLP utilizes job triggers to create a schedule for an inspection job. Whereas scheduling batch data is great for costs and performance, there is the use case for those who need faster inspection of batch data sources. A job trigger can be configured with other GCP services to kick off DLP jobs in near real-time via an event oriented approach. For example, a Cloud Function can be triggered every time a file is uploaded to a GCS bucket.
Batch Data Processing Architecture
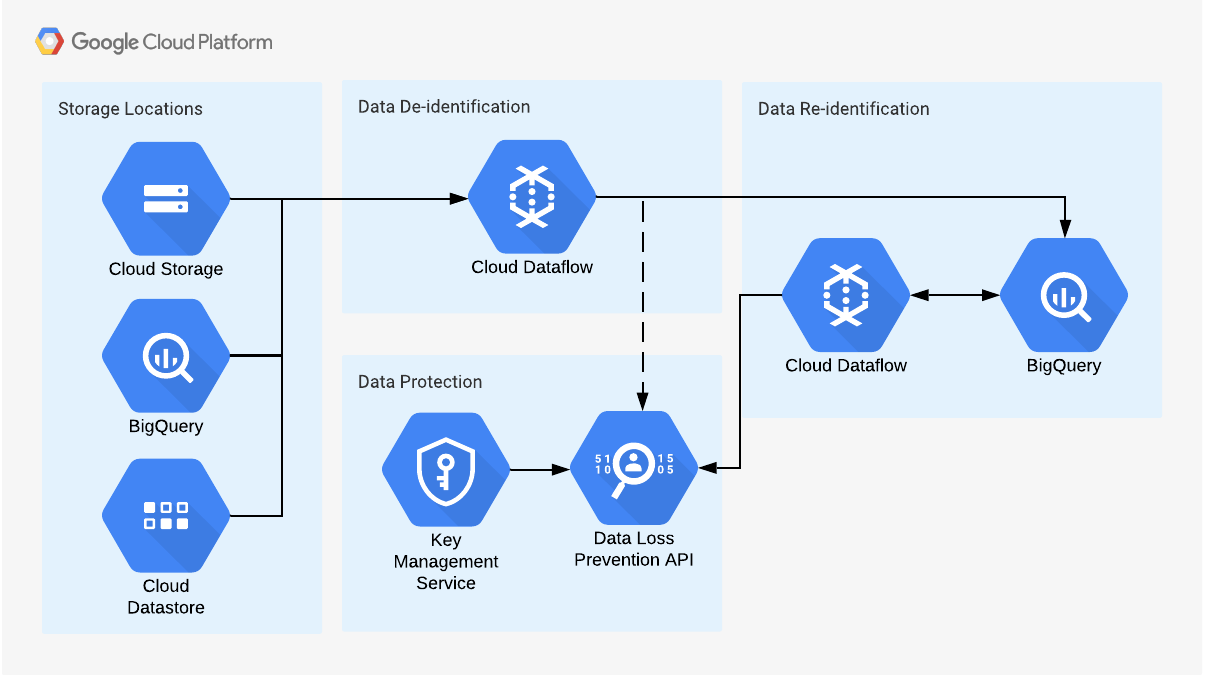
Batch Data Processing Architecture
With this batch data processing architecture utilizing Cloud DLP, data from various GCP sources can be queried by Dataflow through a batch job. Once processed by Cloud DLP, de-identified data is sent to a BigQuery table. When data needs to be re-identified, Dataflow can read data from BigQuery, call the DLP API, and then return the original values.
An alternative use case for batch processing of data for Data Loss Prevention in Google Cloud is to simply redact or alert on data without loading into an external source like BigQuery. For these types of use cases, it is sufficient to schedule jobs using a scheduled inspection. With a scheduled inspection, one simply has to specify a location (in GCS, BigQuery, or Cloud Datastore), set an optional sampling rate, and add an action. Some examples of actions are: publishing inspection results to Cloud Logging, notifying by email, sending findings to Security Command Center (SCC), and publishing to a Pub/Sub topic.
Data Loss Prevention for Streaming Data Processing
In addition to batch data sources, Cloud DLP has support for data sources such as Pub/Sub, custom workloads, and running applications via the SDK. These data sources stream data into GCP services and are continuously ingested by these services, a process referred to as stream processing.
Streaming Data Processing Architecture
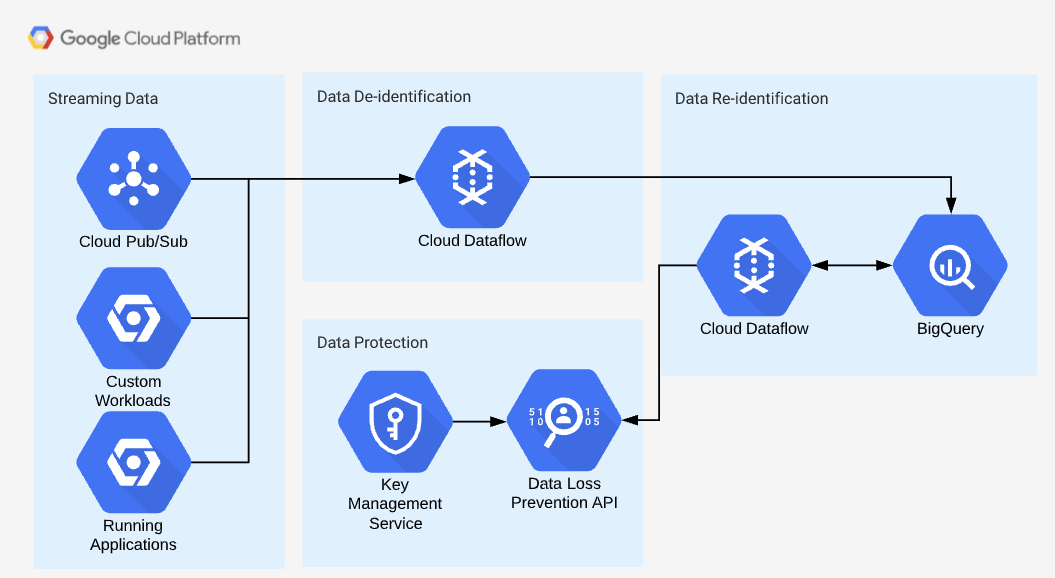
Streaming Data Processing Architecture
Stream data processing architecture is in many ways similar to that of batch processing. The main difference is that Dataflow will be processing the data in near real-time. In a streaming data job, Dataflow can simply subscribe to the sources that may contain sensitive data, de-identify the data via the Cloud DLP API and then store it in a service (such as BigQuery) for analysis. The steps to re-identify data are similar in nature to that of batch processing - when data needs to be re-identified, Dataflow will take the data, send it to Cloud DLP, and return data back into its original form for processing. Note that streaming data will call the DLP API more often, and thus cost and rate limits should be taken into account when implementing this architecture.
Implementing a Data Loss Prevention Pipeline in GCP
Google has a multi-cloud tokenization solution using Dataflow and Cloud DLP in a similar fashion to the examples above. In this GitHub repository, it shows how de-identification and re-identification flows work for both GCS and Amazon Web Services (AWS) S3 buckets. It also goes through the process of using Cloud Key Management Services (KMS) to generate a token encryption key (TEK) to perform tokenization operations. There is also a Google sponsored Terraform module that can be used to set up an example architecture with a controller service account.
Conclusion
The Cloud DLP API is a powerful tool for performing analytics, migrating data securely, and protecting data in the cloud. The workflows we have explored today can be used for both structured and unstructured data as well as both streaming and batch data. Cloud DLP can be used to safeguard data beyond GCP, with example code available that leverages Cloud DLP to secure data in S3 buckets. Tokenizing data at rest in the cloud is an essential part of data protection and can be achieved with ease using reference architectures and infrastructure as code.