

Consistently Optimizing AWS Cloud Costs
At ScaleSec, we primarily think about cloud security — but systems must balance other goals as well, like performance, reliability, and cost. Cost is a particular concern with the consumption model of cloud services, so organizations ask us how to optimize their AWS costs, and we often find over 30% savings. Here’s our approach.
System goals are not always at odds with each other. Removing unnecessary resources reduces cost while limiting risk exposure. Architecting workloads for horizontal scaling not only optimizes cost, but reliability too. Where there are trade offs between cost and other system characteristics, it’s important to consider what your team values more. While you may be able to save some cloud costs avoiding managed services, will the savings exceed the cost of people’s time? Cloud services primarily intend to enable business agility through increased development and delivery speed, so inhibiting those goals to save a little money can be short-sighted. Ultimately these are business decisions and organizations should treat them accordingly.
To consistently optimize cost, organizations should build four financial management capabilities:
- Governance: Plan and measure spend
- Platform: Structure accounts and tag resources
- Operations: Continuously monitor and optimize
- Architecture: Optimize workloads
Governance: Plan and Measure Cloud Spend
To govern cloud spend, organizations should establish a cost optimization function, identify cost attribution categories, and create cloud budgets.
Organizations should establish a cost optimization function — a partnership between technology, finance, and management — responsible for planning and measuring cloud spend. Some call this a FinOps (Financial Operations) team or it may be performed by a Cloud Center of Excellence. The team size and effort needed varies, but it is important to include people across these areas to balance the big picture with local context. Each representative plays a different role. Finance personnel manage savings plans, private pricing agreements, and enterprise discounts. Technology personnel inform decisions based on the architecture and usage patterns. Management personnel make decisions driven by business value and total cost of ownership.
To enable each of these roles, build AWS permissions policies to provide people access to the information and actions necessary for their role. Allow developers access to Cost Explorer, but deny access to Bills or Tax Settings. Allow finance access to costs, tax settings, purchase orders, and bills, while denying them the ability to make environment changes or access controlled data.
This team is responsible for identifying cost attribution categories that map costs to business units, like budgets, cost centers, or projects. AWS Billing provides a Cost Categories feature to aggregate costs across accounts and split shared costs across categories.
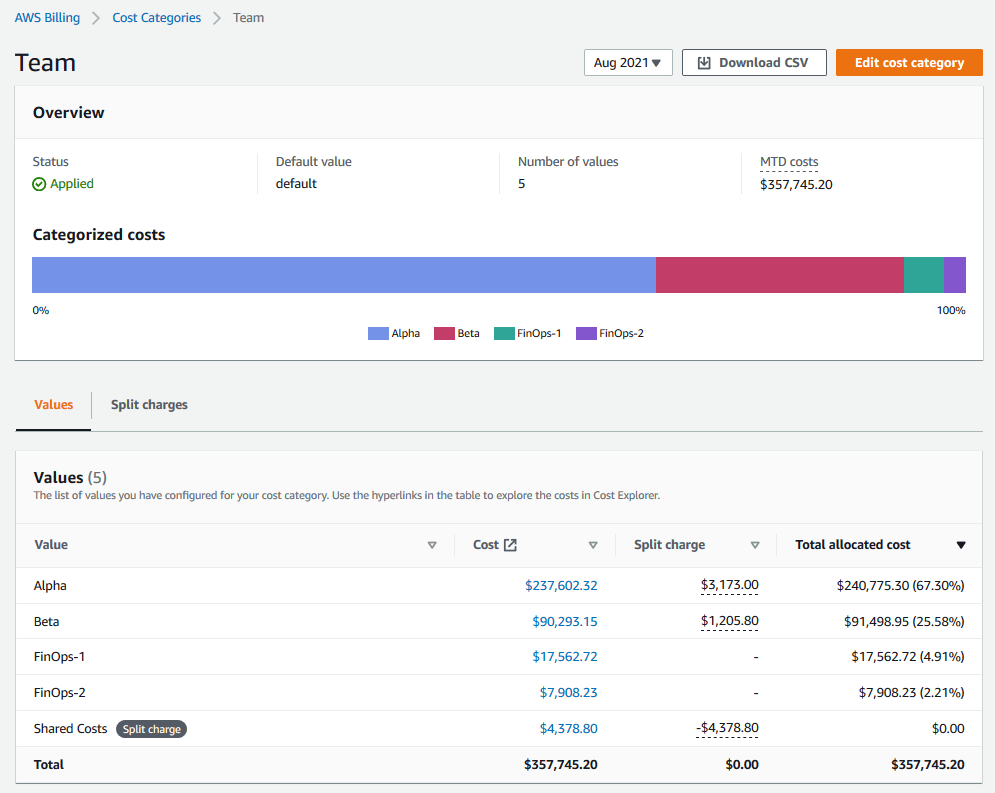
AWS Cost Categories
With cost categories defined, the team then establishes corresponding budgets, forecasts, and alerts. Create AWS Budgets Reports for periodic reporting to management, set Budget Alerts to notify service teams when forecasts exceed expectations, and enable Cost Anomaly Detection to notify engineers about changing cost trends. These reports need to be accessible and timely, as cloud cost overruns can happen fast.
Platform: Structure Accounts and Tag Resources
When resources are organized, it is much easier to categorize costs (and it’s easier to secure them too!) Use AWS Organizations to group accounts into units, create a tag policy, and implement cost controls.
It’s difficult to move resources between accounts without interruption, so plan hierarchical account structures early. Service Control Policies can then be applied at each level, blocking risky or expensive actions. We recommend blocking regions you don’t intend to use, uncommon expensive services (e.g., Sagemaker or Rekognition), expensive EC2 instance types (e.g., ix, 5a, f*), and actions that commit to usage.
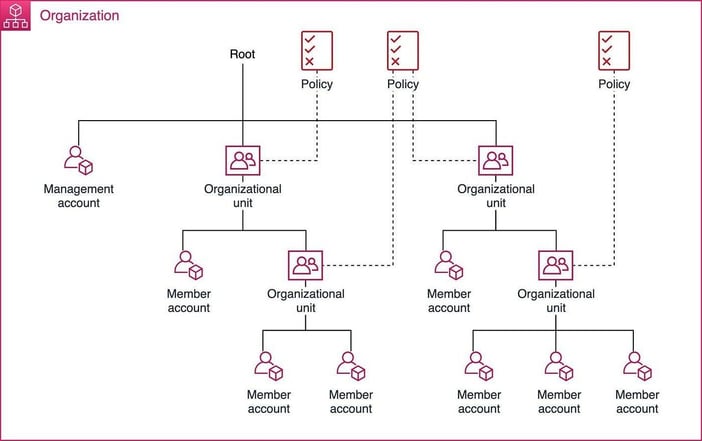
Organizing accounts is important for cost allocation and security policies
For more granular allocation, tag resources according to a standard set of keys and values. AWS Organizations can set a Tag Policy to keep tags applied consistently. These tags can then be used in Cost Explorer, Cost Categories, and even IAM policies. Using Infrastructure as Code (IaC) is essential for consistent tag application — yet another reason to adopt IaC if you haven’t already.
Operations: Continuously Monitor and Optimize
Now that you can measure cost in a useful way, establish a workload review process and monitor cost proactively. The workload review process should consider the appropriate frequency for each workload. Larger workloads may be decomposed into parts. To set the review frequency, consider asking:
- What percent of our overall spending is this?
- How much potential savings could there be?
- How much is this changing?
As you perform reviews, keep a log of potential savings found and how much of those savings were ultimately captured by implementing changes. This way, you can reflect on the effectiveness of the reviews. This process is also intended to foster a cost-aware culture. By consisting asking what can be done to optimize costs, people will begin to make more careful choices.
Proactively monitor and adjust AWS Budgets alerts and cost anomaly notifications. If these have a poor signal to noise ratio, people will just ignore them.

Budget Alerts provide early warning of unexpected cloud costs
Architecture: Optimize Workloads
It would be impossible to precisely prescribe a universal approach to optimizing workload architecture, but a useful heuristic is to search for common pitfalls and apply the appropriate response. There are three primary categories and responses:
- Unnecessary/forgotten resources → Review and remove
- Too big/inflexible resources → “Rightsize”, autoscale
- Inefficient resource usage → Re-architect
I start by identifying the regions and services in use. Then, in order of highest cost, I look for ways to improve. Here are some examples of the most impactful things I look for.
EC2
- How much are we taking advantage of Spot Instances?
- How much are we bursting beyond the baseline CPU of burstable instances?
- Where could we automate stopping instances when not in use?
- What instances could be configured for autoscaling?
- Are we utilizing AWS Graviton for compatible workloads?
- Could this be refactored to be more event-driven?
EC2-Other
This category groups together many things, so I dig into the API operation and usage type.
- Can we avoid inter-zone data transfer?
- Are there idle NAT Gateways?
- Are there unattached EBS volumes?
- Could we default to smaller volumes?
Lambda
Lambda workloads are generally lower-cost unless they are heavily used, but in those cases small changes can make a big difference.
- Can we adjust the allocated memory to optimize the invocation time and cost?
- Can we minimize the deployment package size?
- Are there static assets we can cache in /tmp?
- Can we filter out events that trigger invocations?
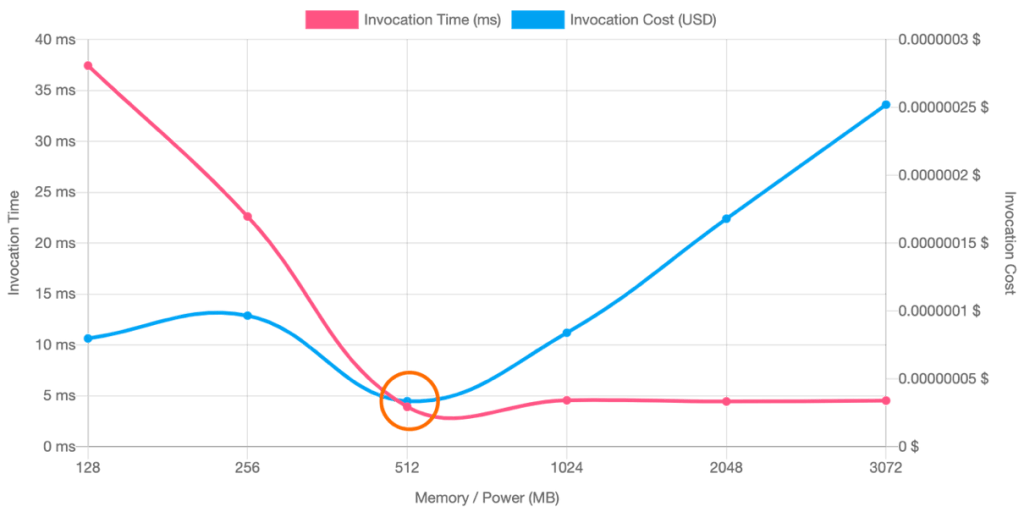
Lambda Power Tuning can help optimize cost and performance
S3
S3 Storage Lens is helpful for visibility and analysis of S3 usage, asking:
- Are we taking advantage of storage classes other than Standard?
- Which buckets have low retrieval rates?
- Are we using Intelligent-Tiering when we don’t know retrieval patterns?
- Have we set Lifecycle Policies to archive and/or delete data?
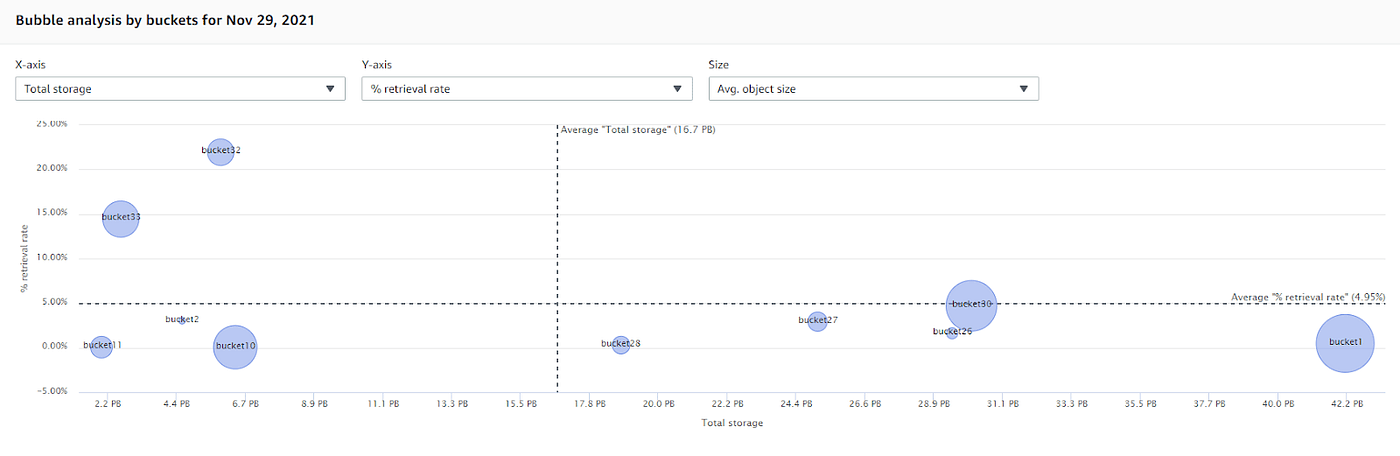
S3 Storage Lens helps analyze bucket usage
Conclusion
Well architected systems balance multiple goals in evolving contexts, so organizations must build capabilities to adapt their systems accordingly. If you are interested in building secure and cost-optimized systems in the cloud, ScaleSec would like to help. Get in touch with us today!