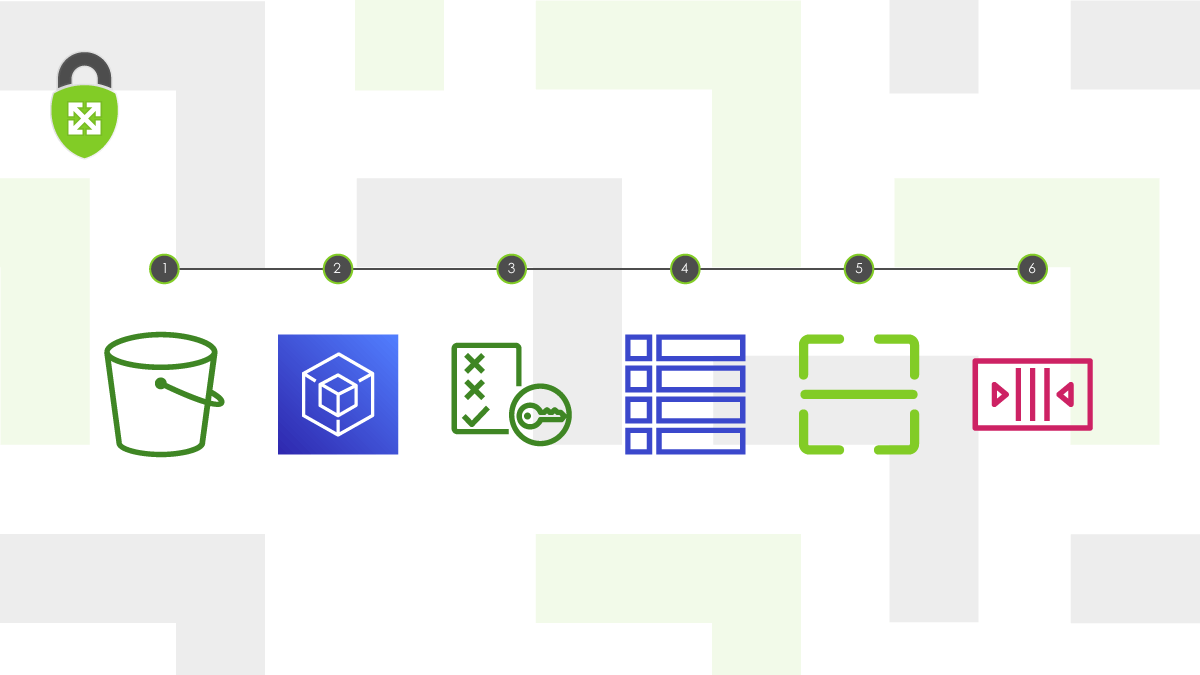
6 Keys to Securing User Uploads to Amazon S3
Amazon S3 is commonly used to provide persistent storage for user-uploaded content in web and mobile applications, given its outstanding reliability, availability, and scalability. However, unrestricted file uploads present significant risks, in particular:
- ❌ You are responsible for the costs of storing the data (Denial of Wallet)
- ❌ The performance of other components may be degraded if overwhelmed by a high volume of data to process MITRE T1499.003
- ❌ Dangerous file types could be improperly handled, abusing application logic or resulting in arbitrary code execution CWE-434.
To mitigate these risks, consider the following approach.
✅ Upload directly to S3
Traditional server-based applications would receive the user-provided content and handle its transfer to a persistent data store, potentially processing it along the way. Instead, allow the application frontend, usually a web or mobile application, to upload directly to Amazon S3. This enables a fast and reliable transfer, without straining your backend application’s resources like network and CPU.

Upload directly to S3
✅ Authorizing direct S3 uploads
We can allow this direct upload by generating a presigned URL that encodes the parameters for a successful request into the URL, including authorization for a specific action. This authorization is temporary, with a configurable expiration time, but can be used from anywhere while still valid. There are two methods of using presigned URLs, HTTP PUT and POST, that appear similar but have a key difference — only POST can enforce restrictions on the uploaded content, like the file size. For that reason, we’re going to use POST URLs.
You can generate a POST URL by calculating the signature yourself, but I don’t recommend it – leverage an AWS SDK instead. The response to generate_presigned_post will contain everything needed, notably an AccessKeyId, signature, and base64-encoded policy. To perform the upload, submit a standard HTTP POST request (you don’t need an AWS SDK) and include the fields returned with the authorization response as form fields. A sample response looks like this:
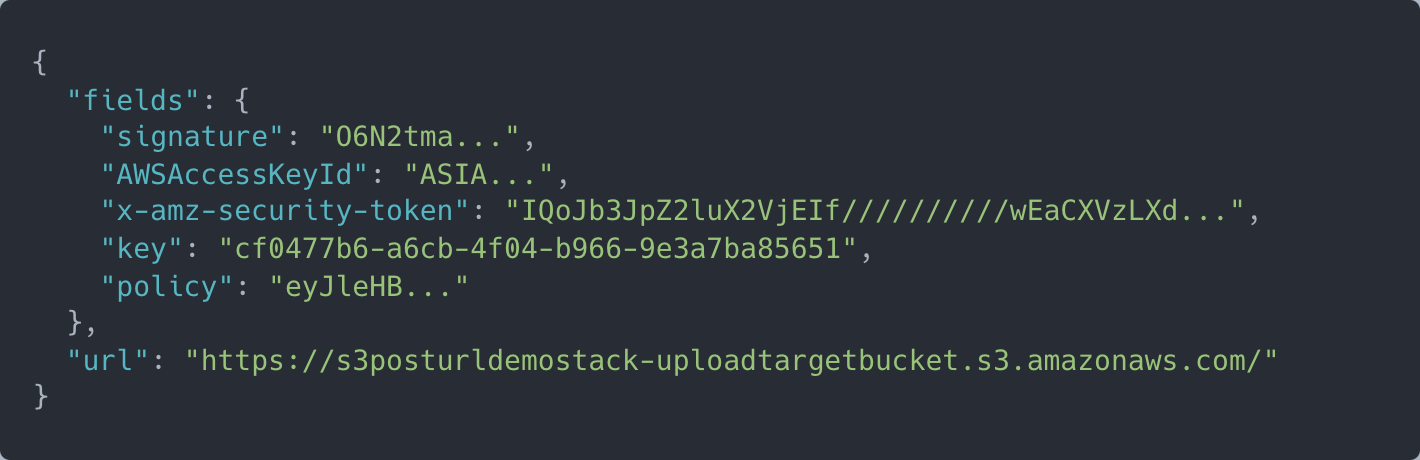
Authorizing direct S3 uploads
✅ Restrict uploaded content
The frontend should still limit the selected content to your desired restrictions, but you can’t trust the frontend to enforce them — the presigned URL can be used anywhere, even multiple times while still valid. A POST policy ensures that requests violating the restrictions will be rejected.
Consider including the following elements in the POST policy.
- S3 bucket and key: We need to avoid collisions, whether accidental or malicious, as uploads with the same key will overwrite existing objects. Additionally, we want to avoid leaking any information in the form of bucket or key names. The best way to accomplish both of these is to generate a random UUID for the key and include it in the POST policy.
- content-type (e.g., “image/png”): You can’t trust that the content will be well-formed, but this will at least prevent uploads that don’t match what you are prepared to process.
- content-length-range: This limits the file size to a range between a minimum and maximum, specified in bytes.
- Checksum (x-amz-checksum-*): If your frontend can determine the checksum hash of the file you want to upload, include it to limit the upload to only that file and ensure data integrity was maintained throughout the upload.
✅ Throttle upload authorizations
You should also consider limiting how much any user can upload. By maintaining a database table of requests, you can check for those limits before authorizing uploads. For example:
- Frequency: rate of user’s requests must not exceed 5 requests in the last 24 hours
- Total size: sum of user’s file uploads must not exceed 2 GB in the last 24 hours
✅ Scan files for malware
S3 has no ability to execute the provided files, so there is no immediate risk of a user uploading malware. However, anything that handles that file downstream could be at risk. Additionally, if your application makes that file retrievable once uploaded, then your S3 bucket could be used to distribute malware to other targets.
There are various open-source and vendor-provided solutions for scanning malware in S3. The major differences are their reporting and response capabilities. Whichever you choose, you should ensure that detected malware is immediately quarantined and can not be processed by downstream systems.
✅ Carefully process data asynchronously
Data processing tasks should be auto-scalable and run independent of other backend functions so they can meet variable demands without degrading the performance of other components. Amazon S3 Event Notifications provide a straightforward way of triggering this processing upon completion of an upload. In general, I recommend sending the event notification to an Amazon SQS queue first, then configuring the processing task (e.g., Fargate task, Lambda function) to pull from the SQS queue. This allows you to handle failures and retries in the queue.

Carefully process data asynchronously
Another major benefit of this pattern is that each uploaded file is processed in an environment isolated from everything else. In the event that a malformed file causes unexpected behavior, it won’t affect other data or processes.
Conclusion
Allowing users to upload files introduces several risks, but we can mitigate them effectively with careful design of cloud architecture. Although these concepts aren’t very new, I still commonly see applications without one or more of them, leaving potential vulnerabilities. Since each application is unique, I build a threat model of the application and consider how these design patterns may mitigate its risks.